Introduction¶
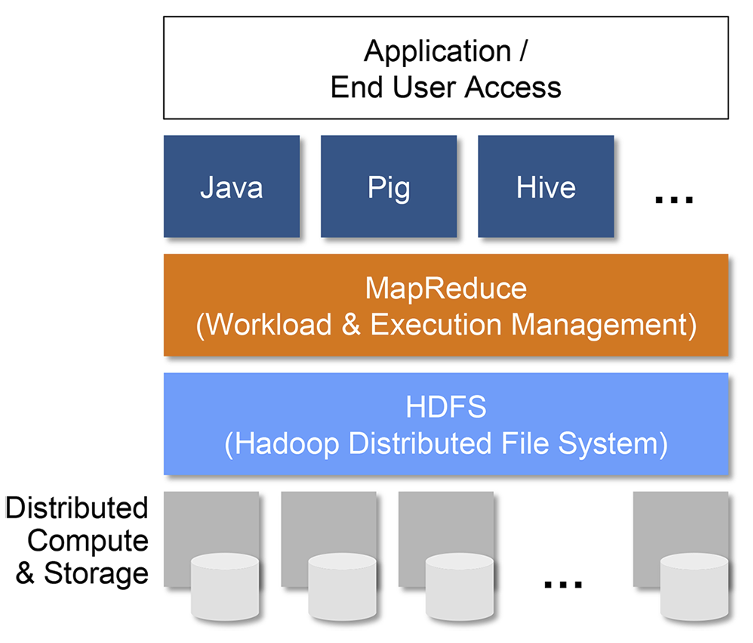
Hadoop Ecosystem¶
An ecosystem for storing and processing large amounts of data.
Basic components:
- Distributed storage
- Computation engine (MapReduce)
- Libraries
- Applications
Designed to run reliably on comodity servers
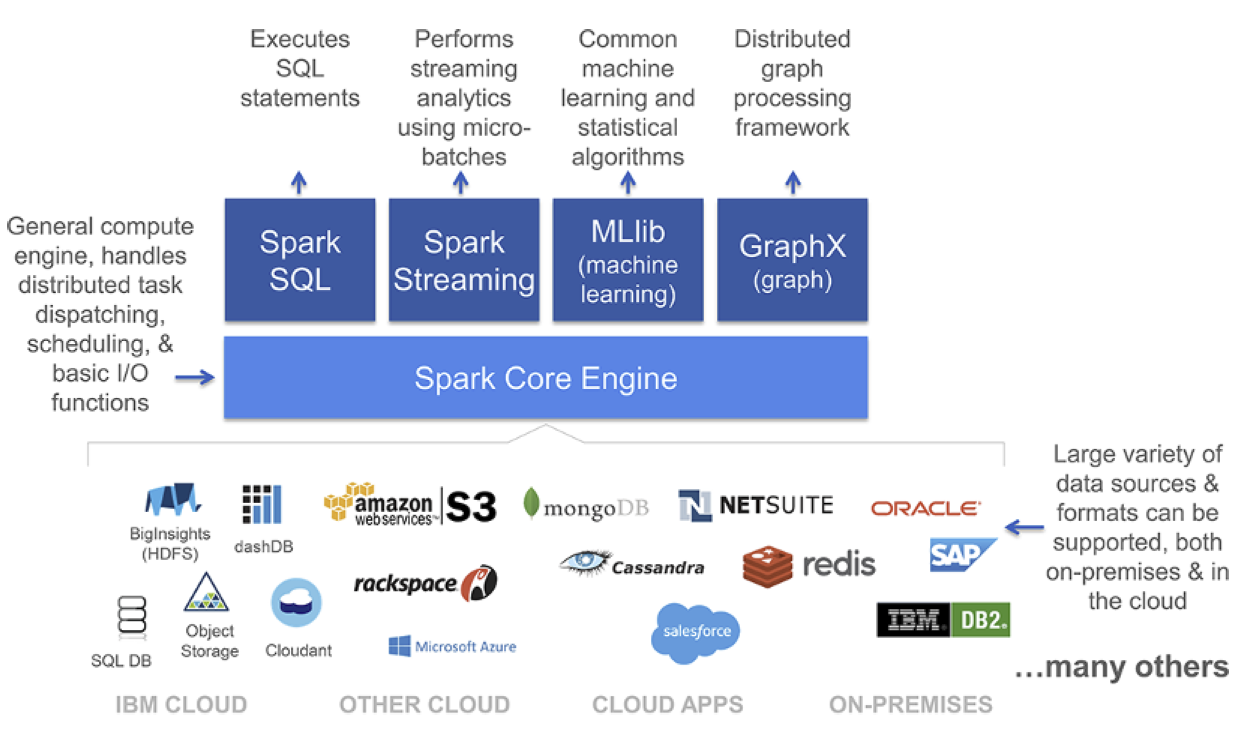
Apache Spark¶
- General purpose in-memory Data Processing engine
- Integrates very well with the Hadoop Ecosystem (and much more)
- Unified engine supporting SQL queries, streaming data, machine learning, and graph processing
- Open source Apache project
Credits¶
The Hadoop and Spark diagrams above are from the Spark for Dummies Free Book
Jupyter Notebook¶
Well, this is a Jupyter notebook :)
It is an interactive document that contain live code, equations, visualizations and explanatory text.
Just like this example below. Try changing the code and then execute the cell by pressing (Shift+Enter).
print('Hello World!!')
x = 2
y = 100
print('{} + {} = {}'.format(x, y, x+y))
print('{}^{} = {}'.format(x, y, x**y))
Jupyter has become the de facto standard used by many data scientist to interactivly analyze data.
Traffic Flow Data¶
In this demo we will be using traffic flow data generated from radar detectors (sensors) that are part of the Motorway Control System (MCS) distributed along the highways in Stockholm (see the picture below for an example).
The detectors generate data every minute. The data contains the average speed and the number of cars that passed in that minute.
The sensors are identified by two fields:
- Ds_Reference: such as "E4S 61,036", which is composed of the road name "E4" and the direction "S" for south, and the kilometer reference.
- Detector_Number: Detectors are numbered from right to left starting from 1 for the first detector in the rightmost lane.

Data Exploration¶
We will use Spark to explore and analyze the traffic flow data. But first we need to load the data and do some cleanup.
Starting Spark¶
We import some libraries that we will be using then initialize spark
### Uncomment to install missing packages as needed (you may need to restart the kernel)
### 1 - ipyleaflet
### Conda package is old (ver 0.3) so using pip instead (ver 0.4)
# !pip install -U ipyleaflet
### or
# !conda install -y -c conda-forge ipyleaflet
### 2 - geojson
# !conda install -y geojson
from ipyleaflet import Map, GeoJSON, TileLayer
from geojson import FeatureCollection, Feature, MultiPolygon
import json
from datetime import timedelta, datetime
import time
import ipywidgets as widgets
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import udf, col, lag, datediff, unix_timestamp
from pyspark.sql.window import Window
spark = SparkSession.builder \
.master('local[*]') \
.appName('Demo4') \
.config('spark.executor.memory', '5g') \
.config('spark.driver.memory', '5g') \
.getOrCreate()
spark.version
Loading The Data¶
The data is stored in a csv file (comma seperated values). Spark can parse csv files and can infer the schema but it is better to define the schema specially when dealing with very large datasets.
Define the schema of the csv file¶
schema_flow = StructType().add('Timestamp', TimestampType(), False) \
.add('Ds_Reference', StringType(), False) \
.add('Detector_Number', ShortType(), False) \
.add('Traffic_Direction', ShortType(), False) \
.add('Flow_In', ShortType(), False) \
.add('Average_Speed', ShortType(), False) \
.add('Sign_Aid_Det_Comms', ShortType(), False) \
.add('Status', ShortType(), False) \
.add('Legend_Group', ShortType(), False) \
.add('Legend_Sign', ShortType(), False) \
.add('Legend_SubSign', ShortType(), False) \
.add('Protocol_Version', StringType(), False)
Read the data¶
Next we read the data and load it into Spark. The data is represented in Spark as a DataFrame wich is similar to a table in a database.
df_raw = spark.read.csv('data/sample_E4N.csv', sep=';', schema=schema_flow, ignoreLeadingWhiteSpace=True, \
ignoreTrailingWhiteSpace=True, timestampFormat='yyyy-MM-dd HH:mm:ss.SSS')
We can inspect the schema to check it.
df_raw.printSchema()
Count the records¶
We count the number of records in the DataFrame. We can add %%time in the beginning of any cell in Jupyter to measure the execution time of the cell.
%%time
df_raw.count()
Print a sample of the data¶
df_raw.show(10)
Data Wrangling¶
Before we start working with the data we usually need to do some preprocessing and cleanup.
In our example:
- Split the Ds_Reference into road name and KM offset
- Convert Km reference from Swdish number format (using ',' instead of '.') to meters
- Fix Detector_Number field
- Filter out records with errors (e.g., detector not working)
Split Ds_Reference and fix Km¶
Spark can take a user defined function udf() and execute it on all elements in a column. udf() takes as parameters a user defined function and the new schema that will be produced.
split_schema = StructType([
StructField('Road', StringType(), False),
StructField('Km_Ref', IntegerType(), False)
])
@udf(split_schema)
def split_ds_ref(s):
try:
r, km = s.split(' ')
k, m = km.split(',')
meter = int(k)*1000 + int(m)
return r, meter
except:
return None
We use .withColume to apply our function to the elements of the column. Using the same column name means the contents will be replaced, otherwise a new column will be created.
df_cleanup1 = df_raw.withColumn('Ds_Reference', split_ds_ref('Ds_Reference'))
df_cleanup1.printSchema()
df_cleanup1.show(10)
Fix detector number¶
Detector number is stored as a character. For example, Detector 1 is stored as 49 which is the ascii code for character '1'. We fix that as well.
ascii_to_int = udf(lambda x : x - 48, ShortType())
df_cleanup2 = df_cleanup1.withColumn('Detector_Number', ascii_to_int('Detector_Number'))
df_cleanup2.show(10)
Using SQL with Spark¶
We can contiune using transformations such as select() and filter() but we can also use SQL.
Spark supports SQL queries which is very useful to quickly explore your data. It also makes it simple for new users to start working with Spark.
For example, we can select only the columns that we are interested in and filter out records with errors (status = 3 is a normal record).
To simplify the visualization, we will focus on a small part of the highway network which is E4 highway North direction. So we will filter that as well.
df_cleanup2.createOrReplaceTempView("FlowData")
df_E4N = spark.sql('SELECT Timestamp, Ds_Reference, Detector_Number, Flow_In, Average_Speed '
'FROM FlowData WHERE Status == 3 AND Ds_Reference.Road == "E4N"')
%%time
df_E4N.count()
df_E4N.show(10)
Plotting¶
We can now start exploring the dataset, for example, by plotting histogram of a column. We will use Spark to do the calculation of the histogram buckets then use Pandas for plotting.
We will extract the column of interest (select()) and use histogram method on RDD. We use flatMap to convert from Row object to int value.
speed_histogram = df_E4N.select('Average_Speed').rdd.flatMap(lambda x: x).histogram(10)
speed_histogram
Then we use Pandas to plot the figure
pd.DataFrame(list(zip(list(speed_histogram)[0], list(speed_histogram)[1])), \
columns=['Average Speed','Frequency']).set_index('Average Speed').plot(kind='bar')

Fundamental Diagram of Traffic Flow¶

We will plot the basic traffic flow diagrams for some of the detectors to get some insights into the properties of the traffic on the highway. In particular, the maximum flow and associated density. We will use that to select thresholds used in queue detection.
But first we need to calculate the density and add it as a new column to our dataset.
Adding Density Column¶
df_E4N_D = df_E4N.withColumn('Density', col('Flow_In')*60/col('Average_Speed'))
df_E4N_D.printSchema()
df_E4N_D.show(20)
Plotting Traffic Flow Diagrams¶
We select one detector and plot its values. In this example we use detector 'E4N 26,050' in the right most lane.
df = df_E4N_D.filter((col('Ds_Reference.Road') == 'E4N') & \
(col('Ds_Reference.Km_Ref') == 26050) & \
(col('Detector_Number') == 1))
df.count()
pdf = df.toPandas()
pdf.plot.scatter(x = 'Density', y = 'Average_Speed', c= pdf['Timestamp'].dt.hour, colormap='Blues', colorbar=False)

pdf.plot.scatter(x = 'Average_Speed', y = 'Flow_In', c= pdf['Timestamp'].dt.hour, colormap='Blues', colorbar=False )

pdf.plot.scatter(x = 'Density', y = 'Flow_In', c= pdf['Timestamp'].dt.hour, legend=True, colormap='Blues', colorbar=False )

We plot for another detector. This one lies in a more congested area.
pdf2 = df_E4N_D.filter((col('Ds_Reference.Road') == 'E4N') & \
(col('Ds_Reference.Km_Ref') == 68960) & \
(col('Detector_Number') == 1)) \
.toPandas()
pdf2.plot.scatter(x = 'Density', y = 'Average_Speed', c= pdf2['Timestamp'].dt.hour, colormap='Blues', colorbar=False)

pdf2.plot.scatter(x = 'Average_Speed', y = 'Flow_In', c= pdf2['Timestamp'].dt.hour, colormap='Blues', colorbar=False)

pdf2.plot.scatter(x = 'Density', y = 'Flow_In', c= pdf2['Timestamp'].dt.hour, colormap='Blues', colorbar=False)

End of Queue Detection¶

To detect the end of queues we will use the density field we calculated. The end of the queue should be close to the detector that experienced a sudden increase in density compared to the density in the previous minute. The end of the queue considered an accident hazard in highways.
To calculate the difference in density we will use the Window function in Spark. A window partitions and sorts the data into groups. Then we can run a computation on the records in these groups (windows). In our example, we will partition the data by the detector unique ID (Ds_Reference + Detector_Number) so we will have all the data for one detector groupd in a window then we sort it by the time stamp.
w = Window.partitionBy('Ds_Reference', 'Detector_Number').orderBy('Timestamp')
Then we define two functions over these windows to calculate the dinsity difference and time difference. We use lag() to access the previous record in the sorted window.
densDiff = col('Density')- lag('Density', 1).over(w)
timeFmt = 'yyyy-MM-dd HH:mm:ss.SSS'
timeDiff = unix_timestamp('Timestamp', format=timeFmt) - lag(unix_timestamp('Timestamp', format=timeFmt)).over(w)
We use these functions to create two new columns in our dataset.
df_diff = df_E4N_D.withColumn('Density_Diff', densDiff).withColumn('timeDiff', timeDiff)
df_diff.show(20)
Because we filtered the original dataset to contain only normal records (we removed records with error codes such as faulty detector or empty highway), some of the records in the window we defined might be more than a minute apart. We filter these records out using the timeDiff field we calculated.
df_diff_min = df_diff.filter(col('timeDiff') == 60)
df_diff_min.show(20)
Now that we calculated the density difference, all what is left is to find the detectors that cross certain thresholds that we define.
df_queue = df_diff_min.filter( (col('Density') > 30) & (col('Density_Diff') > 20) )
df_queue.count()
df_queue.show(20)
3 - Visualization¶
Now that we have found the queue ends (in df_queue DataFrame), it is useful to visualize them on a Map and see them in action. We will use a map widget from ipyleaflet to plot the Geo locations and use a Text Box to show the time.
# Uncomment the map you prefer from the ones below, or add your prefered map source
# Comment all and remove default_tiles to use the default map
#url = 'https://{s}.tile.openstreetmap.fr/hot/{z}/{x}/{y}.png'
url = 'http://a.tile.basemaps.cartocdn.com/light_all/{z}/{x}/{y}.png'
#url = 'http://{s}.tile.stamen.com/toner/{z}/{x}/{y}.png'
provider = TileLayer(url=url, opacity=1)
myMap =Map(default_tiles=provider, center=[59.334591, 18.063240], zoom=12, layout=widgets.Layout(width='130%', height='1000px'))
myMap.layout.height = '600px'
myMap.layout.width = '100%'
myMap
wgt = widgets.Text(value='Timestamp!', disabled=True)
display(wgt)
Detector Metadata¶
To plot the data on the map we need the GPS coordinates of the detector. This metadata exists in a separate geographic information system (GIS). We exported the data into a csv file and converted the coordinates from the Swedish SWEREF99 standard to the GPS WGS84 standard for easier plotting on the map.
Then we load the metadata into Spark.
schema_metadata = StructType() \
.add('Y', DoubleType(), False) \
.add('X', DoubleType(), False) \
.add('DetectorId', ShortType(), False) \
.add('McsDetecto', ShortType(), False) \
.add('McsDsRefer', StringType(), False) \
.add('LaneId', ShortType(), False) \
.add('Bearing', ShortType(), True) \
.add('Location', StringType(), True) \
.add('RegionId', ShortType(), False) \
.add('Entreprene', StringType(), True) \
.add('StationId', ShortType(), False) \
.add('SiteId', ShortType(), False) \
.add('SiteValidF', TimestampType(), False) \
.add('SiteValidT', TimestampType(), False) \
.add('DetectorVa', TimestampType(), False) \
.add('Detector_1', TimestampType(), False)
df_metadata_raw = spark.read.csv('data/sample_E4N_Metadata.csv', sep=';', schema=schema_metadata, \
ignoreLeadingWhiteSpace=True, ignoreTrailingWhiteSpace=True, \
header=True, \
timestampFormat='yyyy/MM/dd HH:mm:ss.SSS')
We split the Ds_Reference like we did with the flow data
df_metadata = df_metadata_raw.withColumn('McsDsRefer', split_ds_ref(col('McsDsRefer')))
df_metadata.printSchema()
Plotting the Detectors on the Map¶
To verify the metada we will plot all detectors on the map. We extract the coordinates from the Spark DataFrame into a local Python list object then plot them.
coord = df_metadata.select('Y','X').collect()
We convert the coordinates into a GeoJson polygon that can be plotted by the map (small triangles)
features = []
for pos in coord:
p = MultiPolygon([ \
([(pos['X'], pos['Y']), \
(pos['X']+0.000001, pos['Y']+0.000001), \
(pos['X']-0.000001, pos['Y']+0.000001), \
(pos['X'], pos['Y'])],) \
])
features.append(Feature(geometry=p, \
properties={'style':{'color': '#0000cd', 'fillColor': '#0000cd', 'fillOpacity': 1.0, 'weight': 6}}))
data = FeatureCollection(features)
g = GeoJSON(data=data)
We can check one of the points
data['features'][2]
And verify that the GeoJson we created is valid
data.is_valid
Add the data to the map. Scroll up and you should see the locations of the detectors plotted on the map.
myMap.add_layer(g)
When you are done. Remov the detectors layer from the map to clean it up
myMap.remove_layer(g)
Add Coordinates to Queue data¶
Now that we have the coordinates of the detectors, we need to add them to the queues we found so we can plot them. For that we use the join operation.
df_queue_coord = df_queue.alias('a').join(df_metadata.alias('b'), (col('a.Ds_Reference') == col('b.McsDsRefer')) \
& (col('a.Detector_Number') == col('b.LaneId')))
df_queue_coord.printSchema()
Visualize Queue Locations¶
We extract the data we need from the joined table in Spark and get it locally into a Pandas DataFrame then loop through it and plot the queue ends we found on the map and show the time in the text box
pdf_queue_coord = df_queue_coord.select('Timestamp', 'X', 'Y', 'Density').toPandas()
We can use the time stamp to get the queues at a specific time and the gps coordinates to plot them. For example:
pdf_queue_coord[pdf_queue_coord['Timestamp'] == datetime(2016,11,1,6,57,0)]
We define some helper functions that we will use in plotting.
Remove all layers on the map except the map tiles.
def map_cleanup(m):
for l in m.layers:
if type(l) != TileLayer:
m.remove_layer(l)
l.close()
Get all layers except the map tiles.
def map_get_layers(m):
layers = []
for l in m.layers:
if type(l) != TileLayer:
layers.append(l)
return layers
Remove a given list of layers.
def map_cleanup_Layers(m, layers):
for l in layers:
m.remove_layer(l)
l.close()
Plots coordinates in a Pandas DataFrame on the map.
def plot_pandas(pdf, m, color='#191970', opacity=0.5):
features = []
for index, row in pdf.iterrows():
p = MultiPolygon([ \
([(row['X'], row['Y']), \
(row['X']+0.0005, row['Y']+0.0005), \
(row['X']-0.0005, row['Y']+0.0005), \
(row['X'], row['Y'])],) \
])
features.append(Feature(geometry=p, \
properties={'style':{'color': color, 'fillColor': color, 'fillOpacity':opacity, 'weight': 5}}))
data = FeatureCollection(features)
g = GeoJSON(data=data)
m.add_layer(g)
We loop through the data minute by minute from start time to end time. To improve the visualization, we plot the current minute in dark blue as well as the previous 3 minuts in lighter blue shades.
# Start Time
st = datetime(2016,11,1,7,0,0)
# End Time
et = datetime(2016,11,1,23,59,59)
# Time Delta
td = timedelta(minutes=1)
t1 = st
t2 = t1 + td
t3 = t2 + td
t4 = t3 + td
while t4 <= et:
l = map_get_layers(myMap)
plot_pandas(pdf_queue_coord[pdf_queue_coord['Timestamp'] == t1], myMap, '#e0ffff', opacity=0.7)
plot_pandas(pdf_queue_coord[pdf_queue_coord['Timestamp'] == t2], myMap, '#b0c4de', opacity=0.8)
plot_pandas(pdf_queue_coord[pdf_queue_coord['Timestamp'] == t3], myMap, '#6495ed', opacity=0.9)
plot_pandas(pdf_queue_coord[pdf_queue_coord['Timestamp'] == t4], myMap, '#000080', opacity=1.0)
# Update time of the Text Box
wgt.value = t4.ctime()
# You may break here to view a snapshot at a specific time instead of animation. Set st to the time you want to check
break
map_cleanup_Layers(myMap, l)
# Change the animation speed
time.sleep(0.25)
t1 = t1 + td
t2 = t2 + td
t3 = t3 + td
t4 = t4 + td
Cleanup the map¶
map_cleanup(myMap)
Next Steps¶
1) Parquet Data Format vs. Original CSV¶
Parquet files are much more efficient than CSV files because they store data in binary and columnar format. Read this for example.
You can test this yourself. We save our cleaned up data in parquet format then use it to load our E4N data. Compare the time!
%%time
df_cleanup2.write.save('data/sample_E4N.parquet', format='parquet')
%%time
df_E4N_test = spark.read.parquet('data/sample_E4N.parquet').select('Timestamp', 'Ds_Reference', 'Detector_Number', 'Flow_In', 'Average_Speed').where('Status == 3 AND Ds_Reference.Road == "E4N"')
%%time
df_E4N_test.count()
%%time
df_E4N_test.show(10)
df_E4N_test.printSchema()
Check also the data size on disk. In my case the csv sample data was 40MB while the Parquet file we saved was 1.4MB!
2) Stream Processing Using Kafka and Spark Structured Streaming¶
The above method for queue detection can be easily converted into a streaming program using the new Spark Structured Streaming. For further reading on that, see this tutorial to get started.
3) Graph Processing¶
Knowing the topological relationship between detectors is needed to do more complicated analytics. For example, knowing next/previous detector on the same lane, knowing detectors before/after lane split/merge.
One way to achieve this is by constructing a graph linking detectors together. Having this graph, we can use graph processing to do more advanced analytics. For example, we can detect queue ends better by looking at multiple consecutive sensors on the same lane.